While there's already a handful of great directory bruteforce tools, the key to uncovering hidden files / endpoints will always be a good wordlist. A common approach I noticed being used by bug bounty hunters is using the same, huge, wordlist everytime. Its clear that this approach will either miss a lot of stuff or take too long due to wordlist size. Chameleon tries to fix this by automatically detecting the technology running on the target server and using a calibrated wordlist. This blog post will document most of chameleon's features and show how to customize it.
https://github.com/iustin24/chameleon
Classic Directory Bruteforce
By default, Chameleon does not attempt to detect technologies and runs just like any other directory bruteforce tool. If no wordlist is is supplied, Chameleon will use the default wordlist. ( ~/.content/chameleon/wordlists/raft-medium-words.txt )
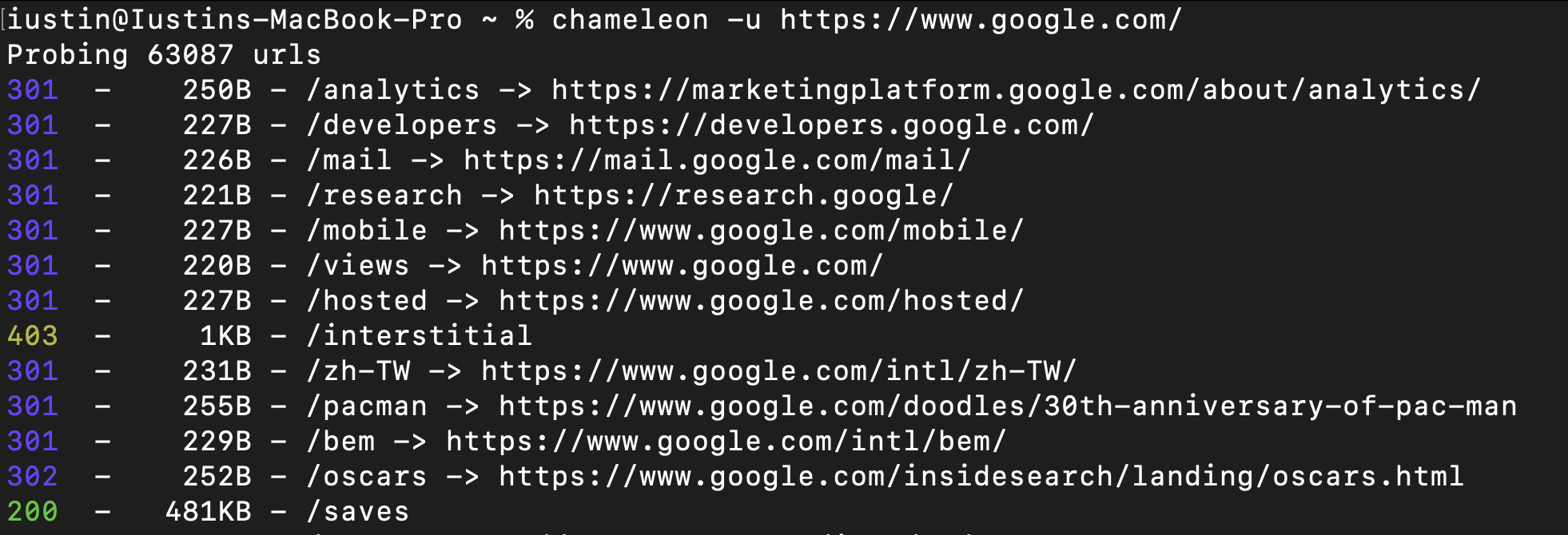
Detect Technologies Automatically
If the -a flag is supplied, Chameleon will load the url in a headless chrome tab and extract the technologies detected wappalyzer. By default, Chameleon will scan the url from -u, however you can change the url used for the technology detection using the -T flag. In order for this feature to work, headless chrome should be installed.
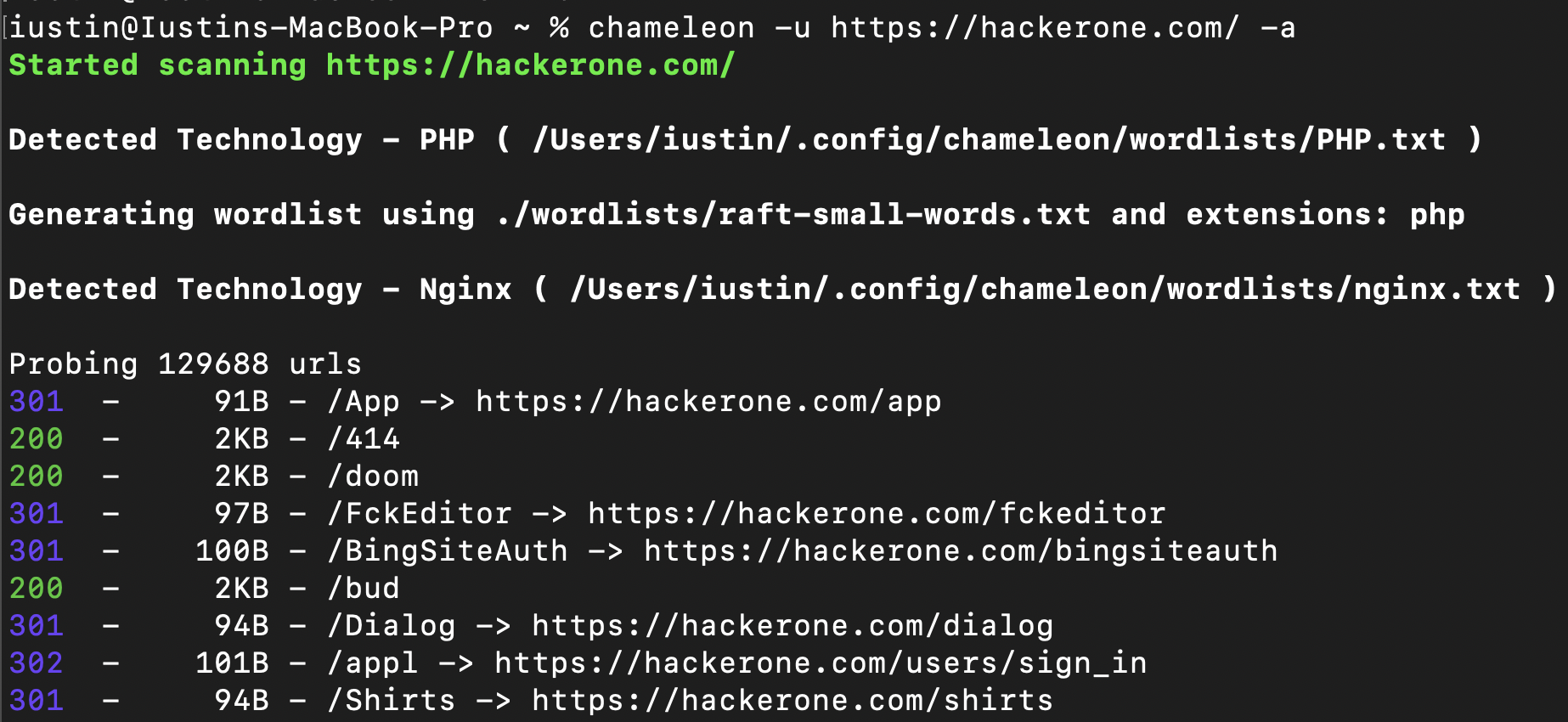
When Chameleon detects a technology it will try do the folllowing:
1. Check if there is any wordlist associated with the technology. If it is, it will add it to the main wordlist.
2. Check if there are any extensions associated with the technology. If there are, it will use the extension to generate a wordlist like so: https://example.com/FUZZ.EXT
3. If the technology detected is Microsoft ASP.NET, it will lowercase all lines from the wordlist.
Custom Wordlists
Most custom wordlists are taken from SecLists or Assetnote, however the Flask, Golang, Spring, Laravel wordlists are generated using Google BigQuery. Credits to Shubs for the idea.
Supply Technologies
It's also possible to supply your own technologies, which will be used even if Wappalyzer does not detect them.

Config file
Chameleon uses the config file located in ~/.config/chameleon/config.yaml.
Changing the default wordlists:
If no wordlist is provided, chameleon will use the wordlist specified in main_wordlist from the config file. ( Default: ~/.config/chameleon/wordlists/raft-medium-words.txt )
When detecting technologies with characteristic extensions, chameleon will generate a wordlist by like so ( FUZZ.%ext ). Chameleon will use the wordlist specified in small_wordlist from the config file. ( Default: ~/.config/chameleon/wordlists/raft-medium-words.txt )
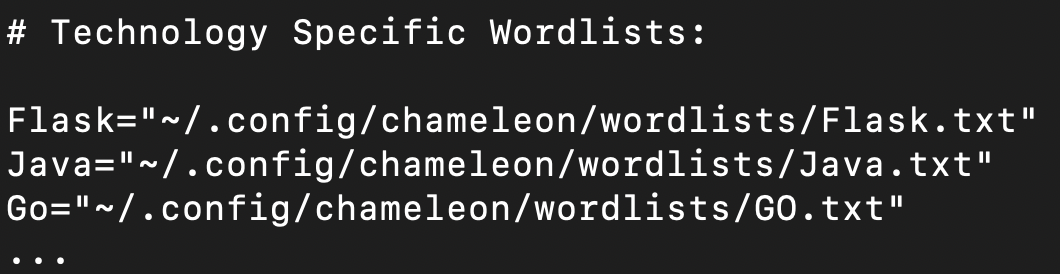
Changing technology wordlists
Example config.yaml with technology specific wordlists:
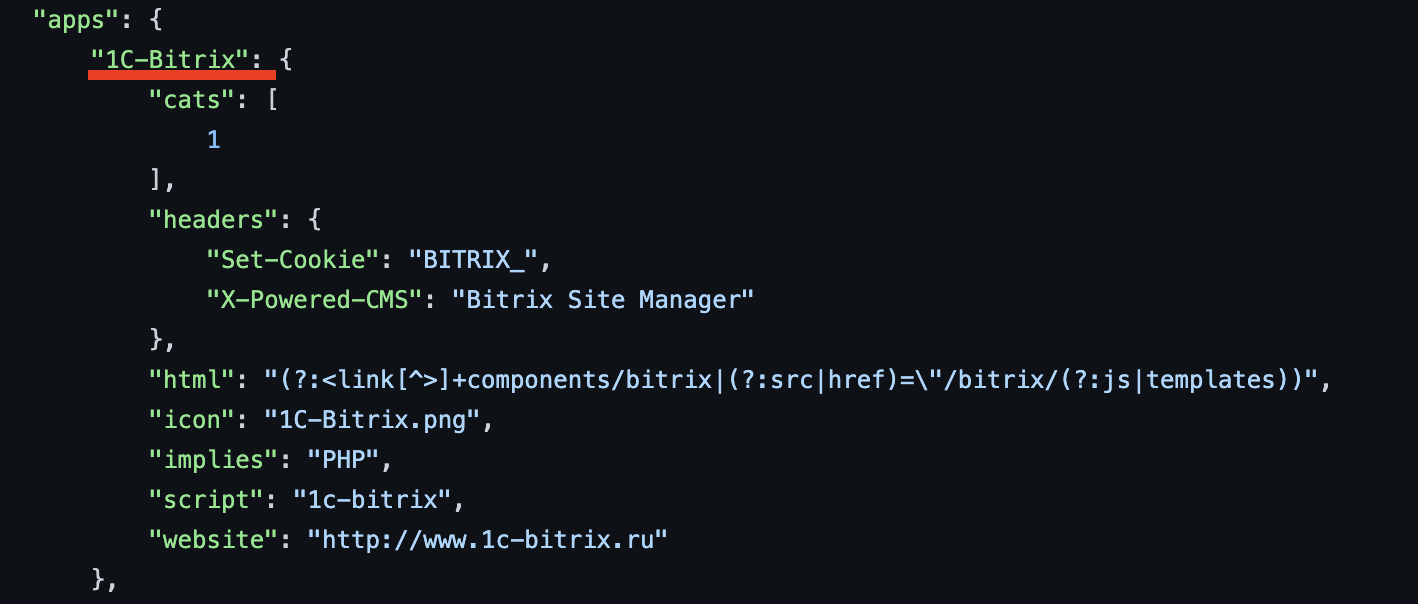
Adding new technology wordlists
Chameleon uses fingerprints from https://github.com/iustin24/wappalyzer/blob/master/apps.json. You can add new technology wordlists by taking the name of a technology from apps.json and adding it to the config file like so:

Adding new extension fingerprints.
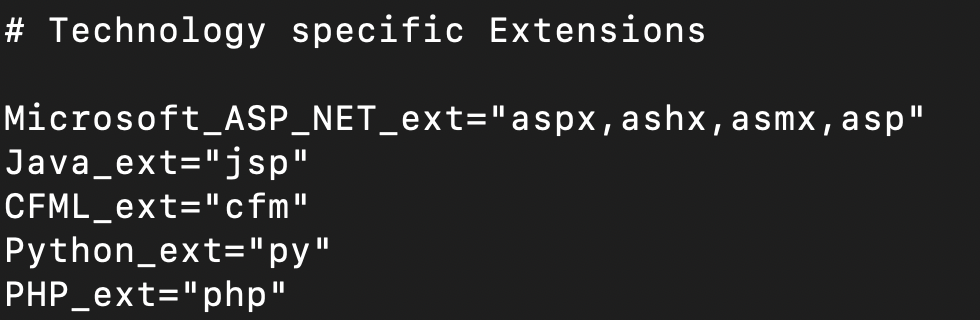
Chameleon generates wordlists using characteristic extensions matching the detected technology. You can add / modify the extensions in the config file like so:
Filtering & Matching
Currently, Chameleon supports filtering based on the response's content length or status code.
-S = Filter HTTP response size. Comma separated list of sizes
-C = Filter HTTP status codes from response - Comma separated list [default: 404]
-s = Match HTTP response size. Comma separated list of sizes
-c = Match HTTP status codes from response - Comma separated list
It's also possible to use the -A flag to automatically calibrate filtering options.
Conclusion
Using Chameleon for directory bruteforcing eliminates the process of manually detecting the technologies used on a host and identifying the correct wordlist to use. As such, not only does it saves time, but it can also lead to the discovery of files/endpoints which would otherwise be missed with a common wordlist. Since Chameleon is still at an early stage, I'm welcome to any suggestions for improving it.